For the last couple of years, I've been lucky enough to spend some time with a MicroServices startup, Traffic Parrot. I've been working with them and their customers, and I have learned a lot about MicroServices.
Last year, based on current and past experiences, the technical leadership wrote a series of technical papers outlining strategies to migrate/start using MicroServices.
This presentation provides an “Executive View” of those strategies and a Framework/Approach to help Executives get started on this journey. The InfoQ articles are a series of technical papers that outline strategies to migrate or start using MicroServices.
While the papers are very technical, I wanted a high-level, top-down view:
And this presentation is about that. It helped me get my hands around the issues, and it will also help other executives if they're trying to figure out if they should go this route or framework or what approach they can use to start this journey.
Monolithic Applications and MicroServices Applications
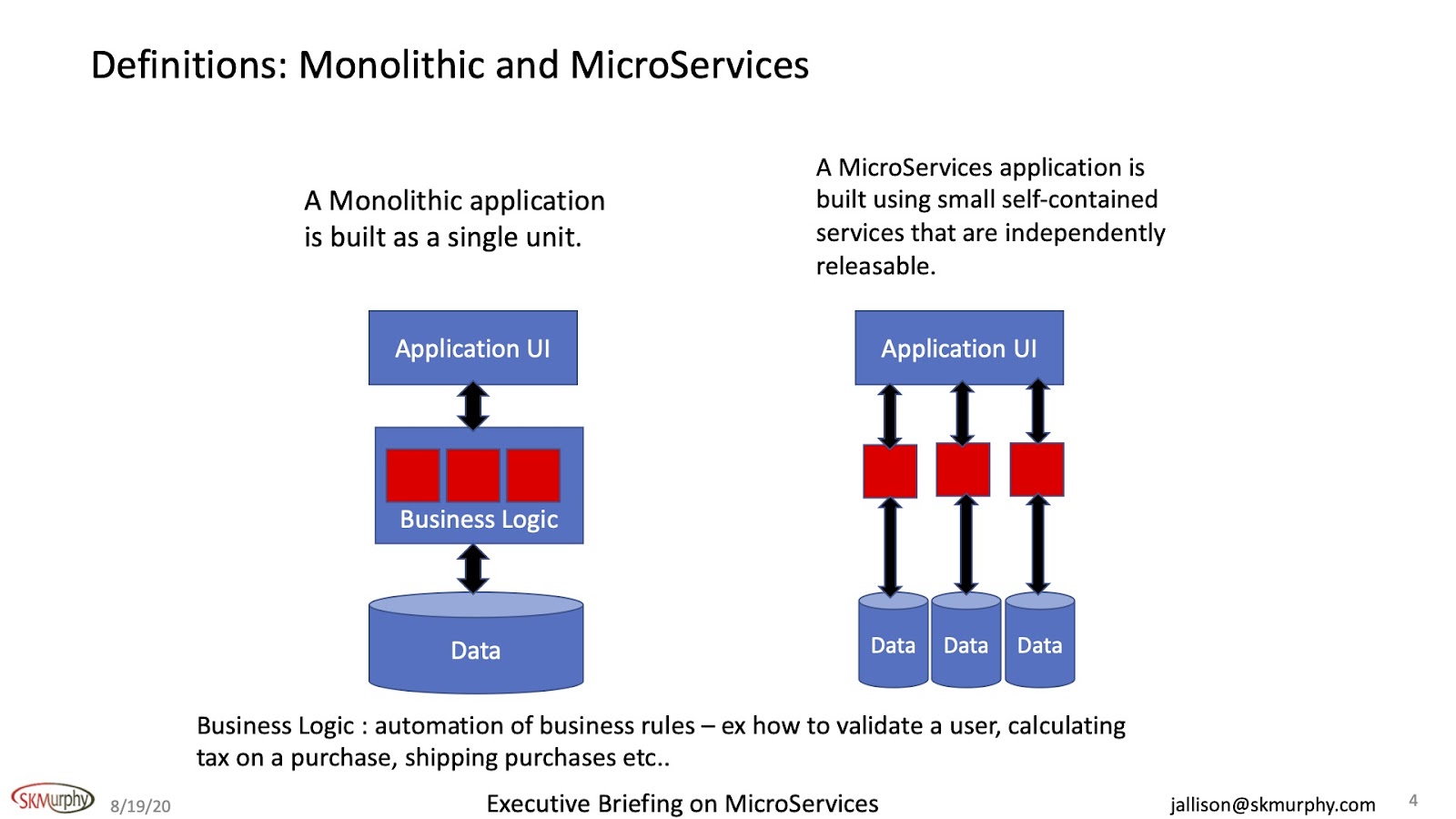
Monolithic applications started through the 1980s to the current day; we are all very familiar with the architecture. A Monolithic application is built as a single unit with a centralized architecture. A MicroServices application is built using small self-contained services that are independently releasable.
A MicroServices application is built very differently. It's made with small self-contained services that, by definition, are independently releasable. But they do the same thing in business logic; they automate business rules, which form a business logic for the applications. And the business rules could be very simple or somewhat complicated. For example, they can validate a user, calculate tax on a purchase, and ship things. So that's my basic definition of MicroService.
Not all Applications need a MicroServices Architecture
Not all applications need a MicroServices architecture. However, sometimes if the complexity doesn't warrant and you try to do a MicroServices architecture, it will probably be more costly than developing a Monolithic application.
Factors to determine whether you should stay in a Monolithic state or go to the MicroServices architecture include:
MicroServices only make sense if the complexity of the problem justifies it. Otherwise, they can be more costly than a Monolith.
What is Promised : MicroServices Over Monolithics
Speed – fast time to quality and performance
Responsiveness – continuous release model
Scale – fast turnaround time
Cost – smaller teams, scalable tools/test footprint
All executives are measured and bonused on .. contribution to the bottom line and customer satisfaction.
Improving speed, responsiveness, scale and cost helps meet these corporate objectives.
Responsiveness improves predictability. Being able to just ship a new feature without the customer having to test the whole system. Gives more visibility and predictability into time-to-revenue. Being able to fix a feature without the customer having to regress the whole system improves customer satisfaction.
Executives are always looking to attract and retain top talent. Enabling next generation development methodologies, supporting best in class tools and infrastructure architectures will go a long way to attracting and retaining top talent.
MicroServices: a lot of Moving Parts
Okay, Why is it difficult? There are a lot of moving parts here, and you have to look at them all. This is what makes it difficult because you will have to put a lot of thought into each of these areas.
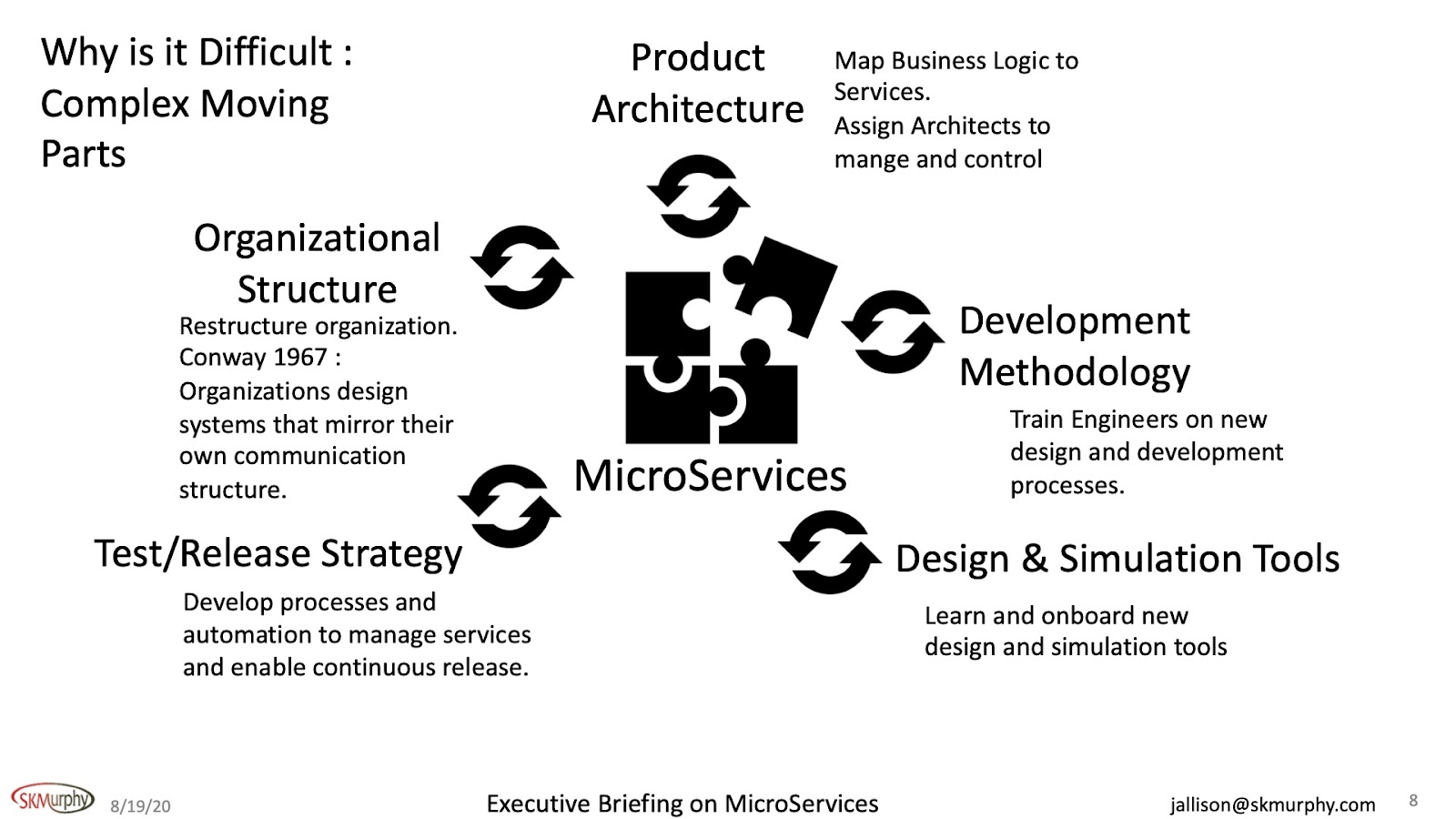
In the product architecture, you need to map business rules to services. For example, the number of services could be in the 100s or even in the 1000s. Due to this scale, you need to assign architects to manage and control the overall architecture of the distributed system.
It's absolutely critical to establish that process because you just can't have people releasing new services without some levels of control and management.
You need to figure out how to train people in new design and development processes on the development methodology. This takes time and dollars. Also, someone needs to drive this effort to make sure it happens.
In design and simulation tools, you will have to onboard these tools and get up to speed on how they work and how to use them effectively.
On test and release strategy, it's not a manual process for a distributed system with continuous releases. You can't put this into an Excel spreadsheet, and one person can't get their head around everything that's going on. So it has to be automated.
Organizational structure is a huge thing. Conway's law says that organizations design systems mirror their communication structure. So, if you've got a decentralized application architecture and a central organizational structure, you've got a problem, and it's hard. Believe me, I've tried to break down higher-level organizations or more central organizations into small and manageable blocks. The inertia there is huge. It's a very tough problem, but you've got to figure out how you manage that if you're going to go this way.
What we did observe, too, since some companies couldn't do this too well, and they ended up with a distributed monolithic, which causes maybe more problems than they were trying to solve in the first place.
Key Risks with MicroServices:
Focus on security and governance
Make sure you have enough telemetry data to diagnose issues in a distributed system
Lack of infrastructure and test automation will impact any MicroServices efforts at scale
Conway’s law - communication patterns between teams
I wanted to talk about some of the risks. Governance: you need people to manage the introduction of new services to the overall structure.
Security is, in my mind, a big issue. In a decentralized MicroServices structure, you've got all these services, and they tie together with APIs. Unfortunately, each one of these interfaces is a security issue. So the governance body, or this team of architects, needs to cover their security bases. They need to make sure that they've done everything possible to minimize the impact of any break-in into these structures that causes a security issue.
A decentralized MicroServices structure is massive. In some ways, that's what you want. You want to create an environment where you can very, very quickly introduce new features and functions. Still, you've got to have enough telemetry data to diagnose issues in this distribution system. You can't manually track it. This is not a spreadsheet operation. You need tools to give you visibility into what's happening in this structure.
Lack of infrastructure - if you're not making the right investment and you're not doing the right level of test automation. Any efforts you have to scale MicroServices, they're going to be really, really hard. Do the heavy lifting up front, you'll benefit in the backend, because you've done the hard work.
Earlier I talked about Conway's law of communication patterns between teams. There's also Amazon’s two-pizza rule for teams. They say that if you can't feed the team on two pizzas, the team's too big and needs to get smaller. In my experience, smaller teams move a lot faster. Also, I'd be seeing decentralized organizations move very, very quickly over more central groups. But I've also seen the challenges in organizing and managing decentralized teams because there are many moving parts, and everyone's moving lightning fast.
Cost & RIO - Monolithic vs. MicroServices
Need to invest up front in people, process and tools to benefit later.
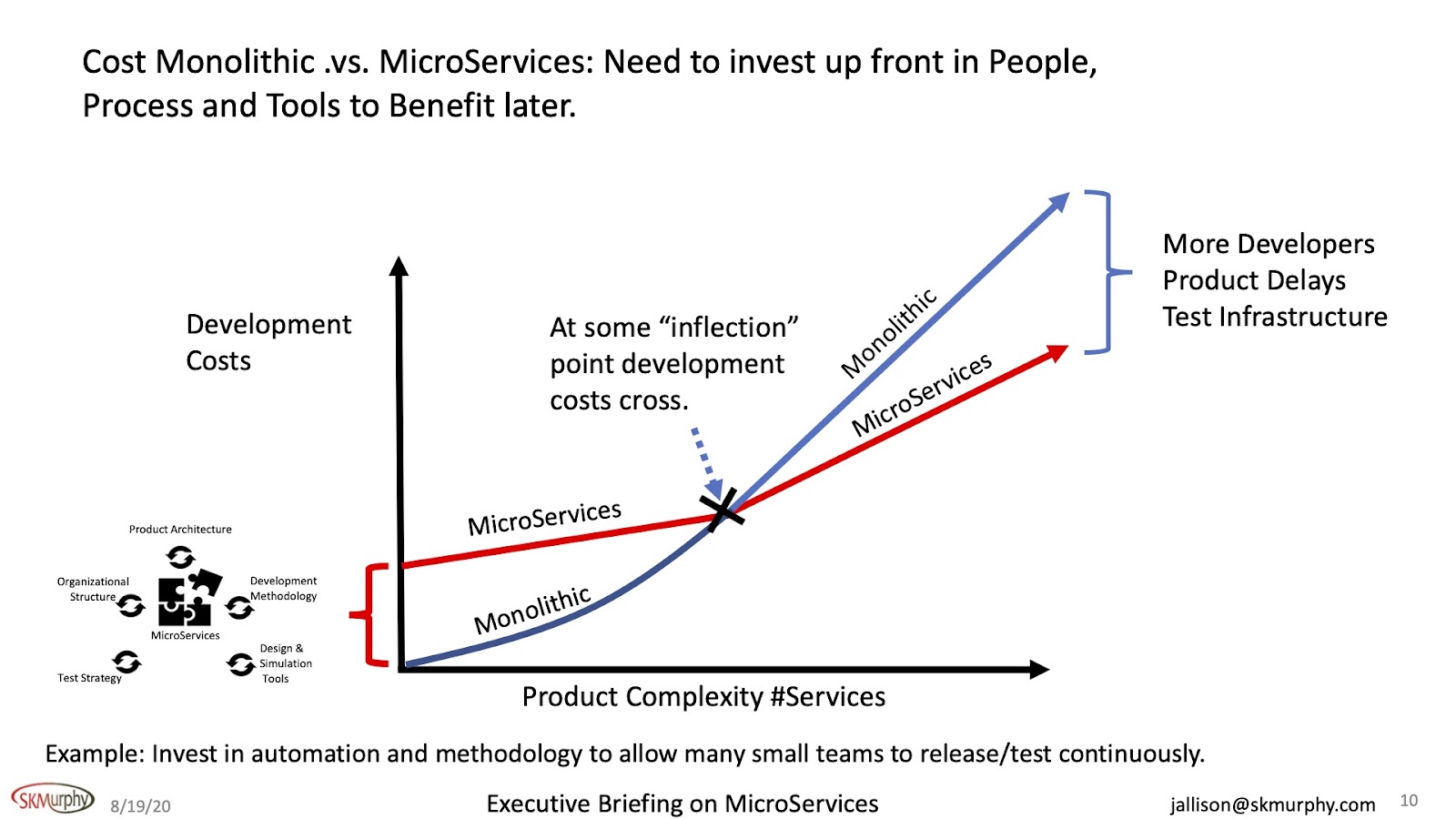
In this chart, I am showing the trade-off here between complexity and development costs.
Initially, MicroServices cost more than what you are currently doing. This initial cost includes:
Training on development methodology
New tools
Figuring out the process and strategy
Mapping out product architecture and developing structures to protect myself from lots of changes, and rapid growth in my code base.
Figuring out the organizational changes
The question is, is there a difference in reliability between Monolithic and MicroServices applications?
I believe so because if you look at it from a test perspective and measure reliability in big Monolithic. When looking at individual components, it's a lot harder to validate the complex interactions internally to that structure. People generally look at the inputs and then just watch the outputs.
Whereas with a MicroServices architecture, you have full visibility, controllability, and observability between all of those different components. So inherent by definition, the ability to better control and better observe gives you faster time to observe a problem and fix any reliability issue.
Okay, so there are two big takeaways from this diagram. First of all, there are some dollars involved, and they could be significant. And then, we're not going to realize any benefit for some time, and that's always a problem.
Setting Expectations
You try and get some dollars to do something, and it is significant dollars. And then you say, "Well, you're not going to realize this until down the road," always gets people's attention. So, this is important. And why is it important? Because you need to set the expectations.
You need to set the expectations correctly upfront to understand that my ROI doesn't happen until somewhere in the future. So you will need to have a plan and a schedule with milestones to communicate the trajectory and what the impact will be to the company over time, and when we're going to start to realize that we're on this trajectory. So the big takeaway here was to set the expectations so that there are no surprises.
Scaling - Monolithic vs. MicroServices
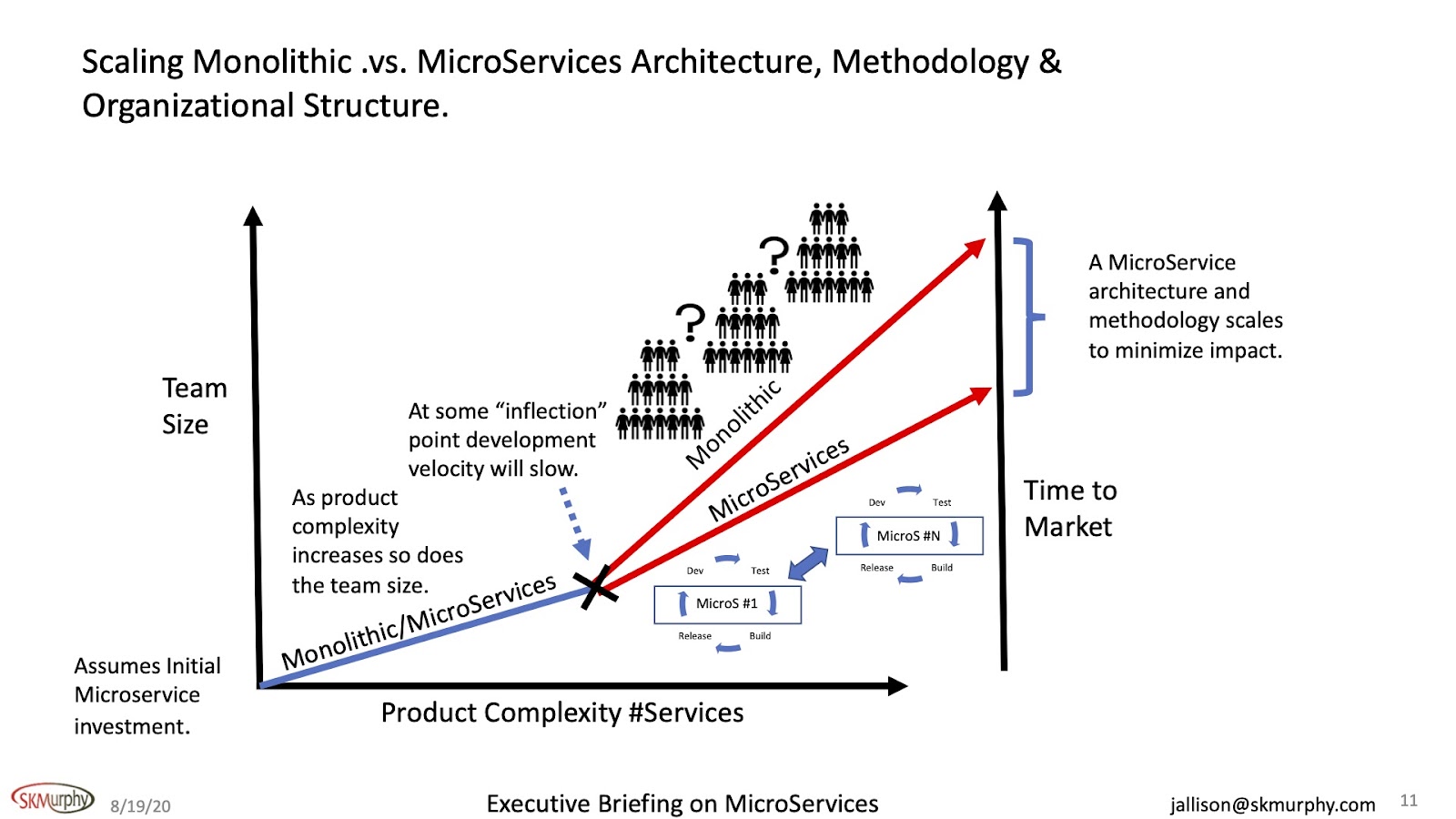
Let’s take another look at cross-reference and team size here with product complexity. I'm assuming here that we've made an initial investment in MicroServices so that I've got a MicroServices methodology going alongside a monolithic development. Initially, they more or less follow the same path.
I am assuming that as the complexity increases, so does team size. That's not always the case, but happens enough of the time that it is a reasonable assumption. At some point, the development velocity is going to slow.
In a central structure, as you bring new people on board, they need to understand how the whole thing works. Because individual components may be dependent on each other, everyone on the team needs to understand everything. Many of these systems have been out there for a while. Documentation does not reflect reality. People that worked on it are no longer there. So these new folks, they become pretty creative. They start to think, "Well, I think it works this way, so therefore, I'll do this, or I'll put a wrapper around it to make it more understandable." Whatever it is they do, the curve for learning goes up. It takes a long time to get their arms around what they're supposed to be doing.
Scaling in a MicroServices Architecture
If done right a microservice architecture protects small teams from unknown or surprise dependencies. They don’t need to know or care about how the whole system works. They only need to understand what business rule or feature they need to code and the input and output of the service they are coding. This allows me to bring on small teams of engineers very quickly and to have an impact very quickly.
Testing MicroServices Techniques
To change up on you a little bit here, I'm going to talk about testing. To test your software, you need a test strategy. As I said earlier, it's not a manual process. It has to be automated.
The testing strategy needs to involve both a combination of real resources and virtual resources.
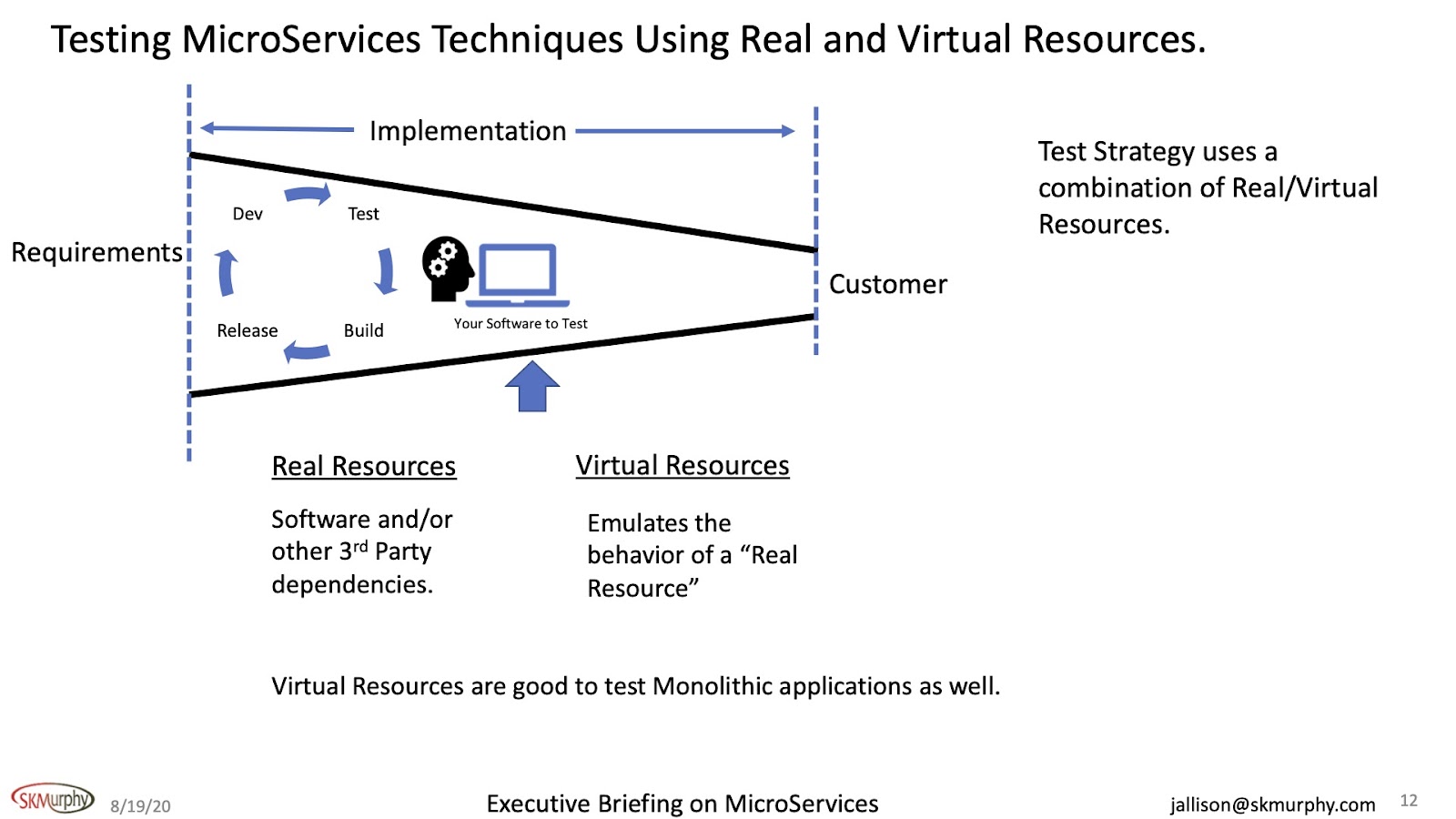
Real resources include:
Another software module test and/or production
Production/shipping software
Hardware dependencies servers etc.
3rd party software (AWS)
Note about real resources: They are difficult to scale as system complexity increases.
Virtual resources include:
Virtual resources provide more flexibility to a divide and conquer test approach. Virtual resources provide test capability not possible using real resources. Sometimes the real resources aren't available to you, and what you're going to do? Are you going to wait? No, you've already invested in this decentralized model to make you move fast. Why wait on a resource to test your stuff because it's just going to slow you down.
So you invest in technologies that allow you to emulate the behavior of a real resource because it's not available or hasn't been written yet. This takes work, investment and expertise, but it's critical to continue to develop quickly. Resources like hardware might not always be available. When we were developing some really expensive high-end technology, we had to then go to a 7/24 model and schedule developers’ time on it. As an executive, you just don't want to put anything in front of engineers that's going to slow them down, especially if you can solve it. You just want to take away any barrier and give the right level of resources to an engineer at the right time. It is the only way we can get the throughput that we wanted to realize.
With virtual resources to emulate that the hardware, I can put as many of these as I want in front of any number of engineers that I want. So I'm removing that bottleneck.
Also with virtual resources, there are some things that you can do that you can't do with a real device. If you had to run against a real device for a certain amount of time before you got to the point where you wanted to test out some new feature, that's a waste of time. If you had a virtual resource, I could just jump straight to that point and then test from there.
It's difficult to scale real resources as the system complexity increases. In a distributed model, you're going to need advanced simulation technology to help you use the methodology for your organization.
Greenfield: Start New Product with MicroServices?
Starting with a MicroService, only makes sense if you've already made the investments in the MicroServices methodology, like all the things that I talked about got a handle on and you've got the abilities to do this.
If you don't, then you should start with a monolithic and then plan to go to a MicroServices architecture later. So the nice thing I like about this approach is you can use this monolithic and you can probably get out there much faster. You can use it as a fast prototype. So you could be out there with this monolithic thing and you could be making lots of iterations, understanding what people are doing with it, how they're using it, come back, modify it, come back, modify it and start looking at your dials: application complexity, size of team and business requirements.
Move to MicroServices when you have crossed the complexity boundary. When managing a monolithic application is going to slow you down.
The only problem with this is it's too serial. I mean, what you need to be able to do is you need to say, "Okay, I'm running along here with my fast prototype, this monolithic. I imagine maybe at some point I need to change to more of a MicroServices. Let me measure along the way and predict. I can start a parallel MicroServices architecture.
I've got a Monolithic app and I can go to the MicroServices app. Microservices app is not ready for prime time, yet I'm working on itl. When I get to this point that I'm measuring, I'm using some indicators here, I just cut over.
I think that's the way in which you should use that. Get out there quickly, get some feedback, understand it's going to go that route, start working in parallel and then cut over. There's no disruption to your store base. Then you're off and running and utilizing all the benefits you get from this architecture. The issue here is parallel. That's always dollars, more people.
Wrap Strategy
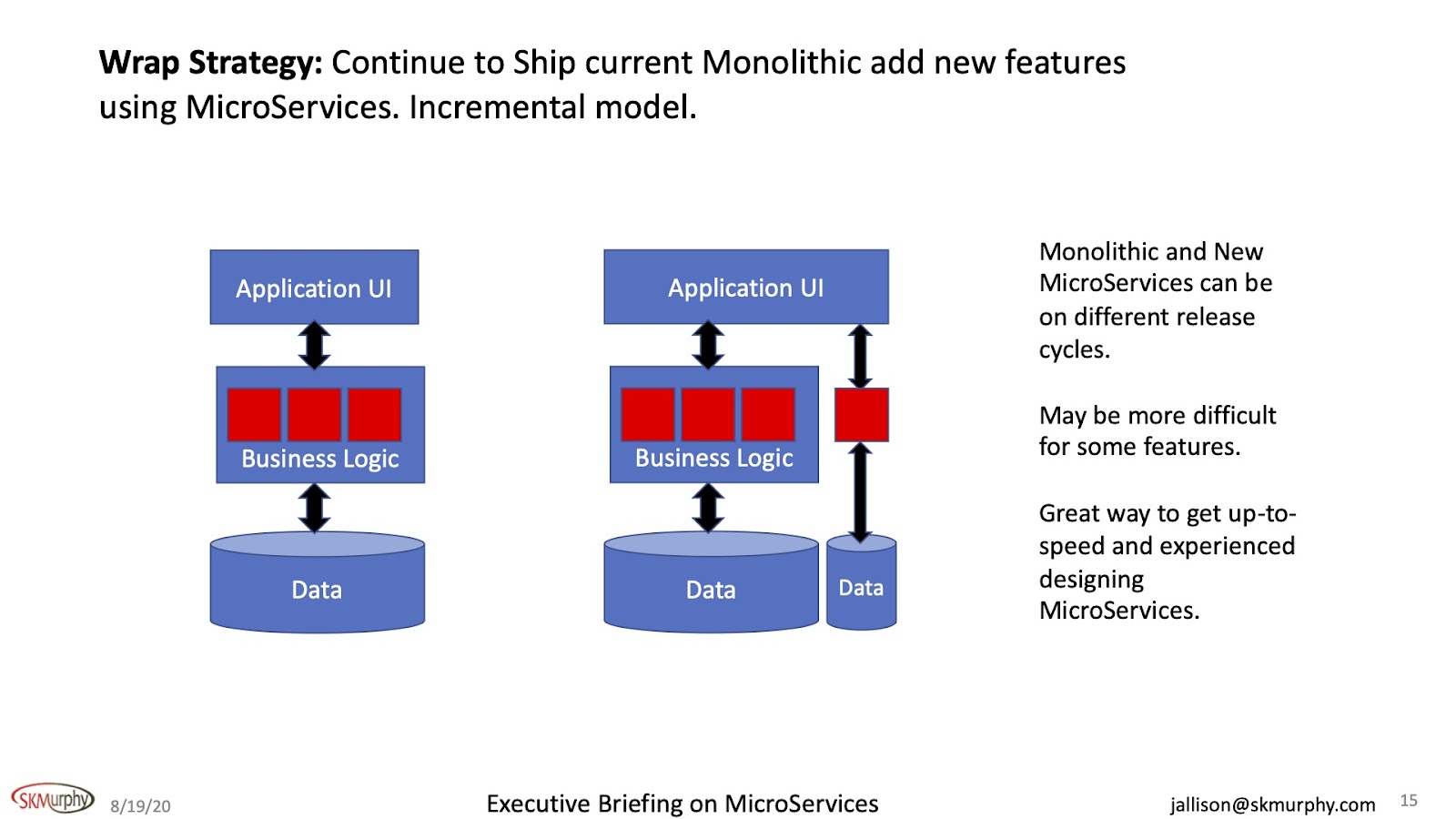
Another way to get started is to continue to ship the current model. You've got this thing, it works, ship it. Anything new, make a MicroServices. Now, this may be more difficult for some features, I'm absolutely sure of it. But conceptually, if you can do this it makes customer acceptance of this new feature much simpler, faster and cheaper because they only need to test the new feature. If this feature was released in the monolithic they would have to regress the whole system.
These features could be on a different release cycle. The monolithic could be on a 3, 6, 9 months cycle. Whatever makes sense. The release cycle of the new feature could be every day. And this is a great way to get started.
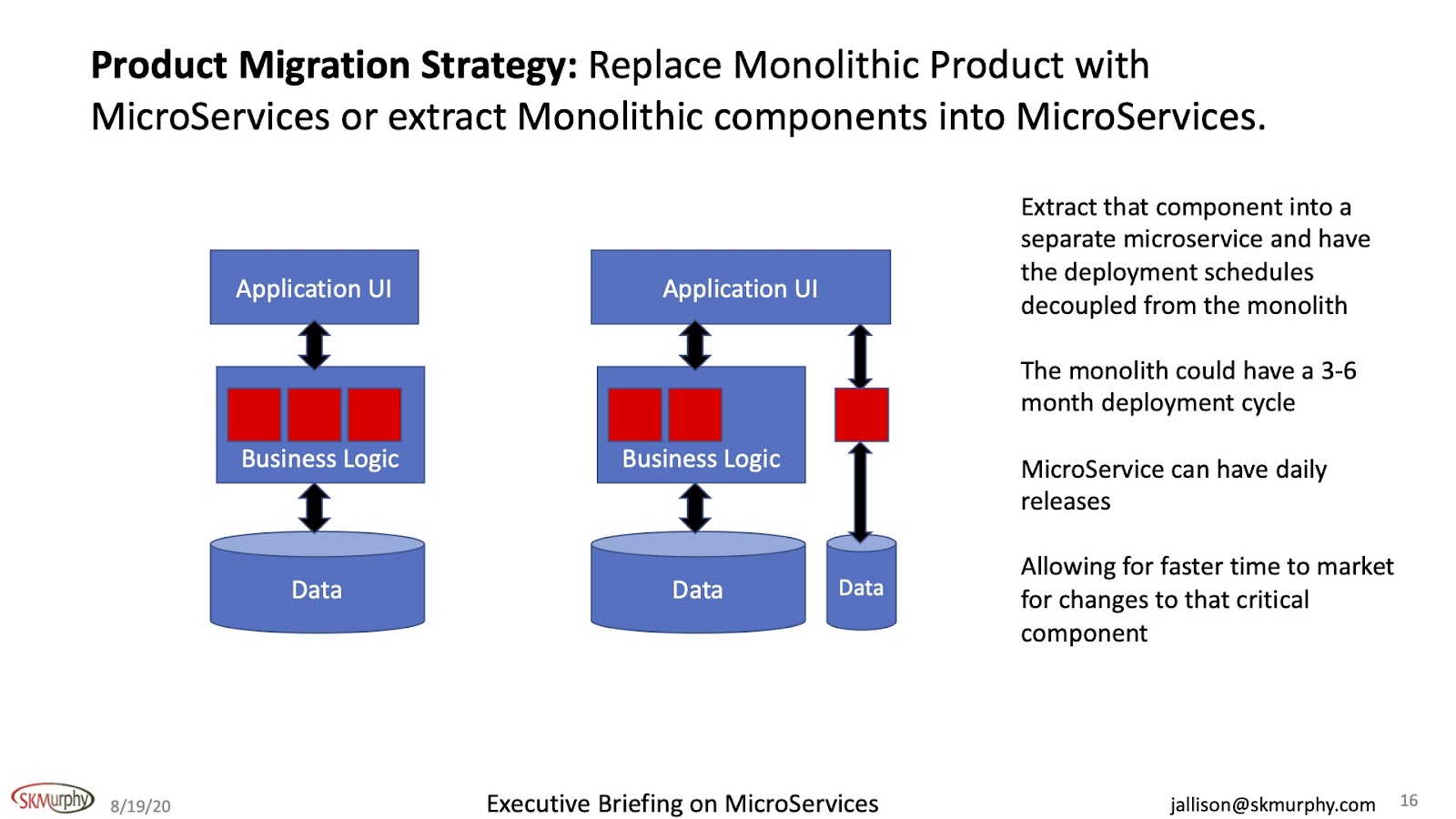
Along the same lines, instead of adding something new, pull something out. So, I've always had a problem with this function. This component has causes a lot of problems and I need to change it often. Why don't I just pull it out of here and then all this stuff that I don't need to change often, stays where it is.
This problematic component is coded and developed and shipped with a MicroServices methodology. It just works for me again. The other components are on different release cycles and the MicroServices component is daily with supports for quick revs.
Test Migration Strategy

Let’s talk about a test migration strategy to use virtual services for monothitlics. Everything I have talked about with microservices architectures, for testing and virtual resources can be applied to monolithics too. Say my current test environment requires a production database or a live 3rd party resource. These may be difficult and expensive to schedule and utilize. I could emulate that database or 3rd party service using a virtual resource. What I talked about simulation for microservices also works for monolithics.
Key Points and Takeaways
Not all applications need to be MicroService.
Many ways to start :
Monolithic first then MicroService
Add new Features as MicroService to Monolithic
Replace components of a Monolithic with a MicroService
Need to invest in people, tools and process
Need to plan carefully and set expectations internally